| 出品公司: | Clontech |
|---|---|
| 载体名称: | pAcGFP1-1 |
| 质粒类型: | 无启动子载体;荧光报告载体 |
| 高拷贝/低拷贝: | 高拷贝 |
| 克隆方法: | 限制性内切酶,多克隆位点 |
| 启动子: | 无启动子 |
| 载体大小: | 4150 bp |
| 5' 测序引物及序列: | -- |
| 3' 测序引物及序列: | -- |
| 载体标签: | 绿色荧光蛋白AcGFP |
| 载体抗性: | 卡那霉素 |
| 筛选标记: | 新霉素(Neomycin) |
| 克隆菌株: | DH5α, HB101 |
| 宿主细胞(系): | 真核细胞 |
| 备注: |
pAcGFP1-1载体不含启动子,将待研究的目的启动子插入MCS区,用于研究启动子及顺式转录元件在细胞内的作用水平; AcGFP荧光亮度高。 |
| 产品目录号: | 632497 |
| 稳定性: | 瞬表达 或 稳表达 |
| 组成型/诱导型: | -- |
| 病毒/非病毒: | 非病毒 |
买家导航

pAcGFP1-1载体质粒基本信息
pAcGFP1-1质粒图谱载体图谱和pAcGFP1-1载体序列质粒序列多克隆位点信息
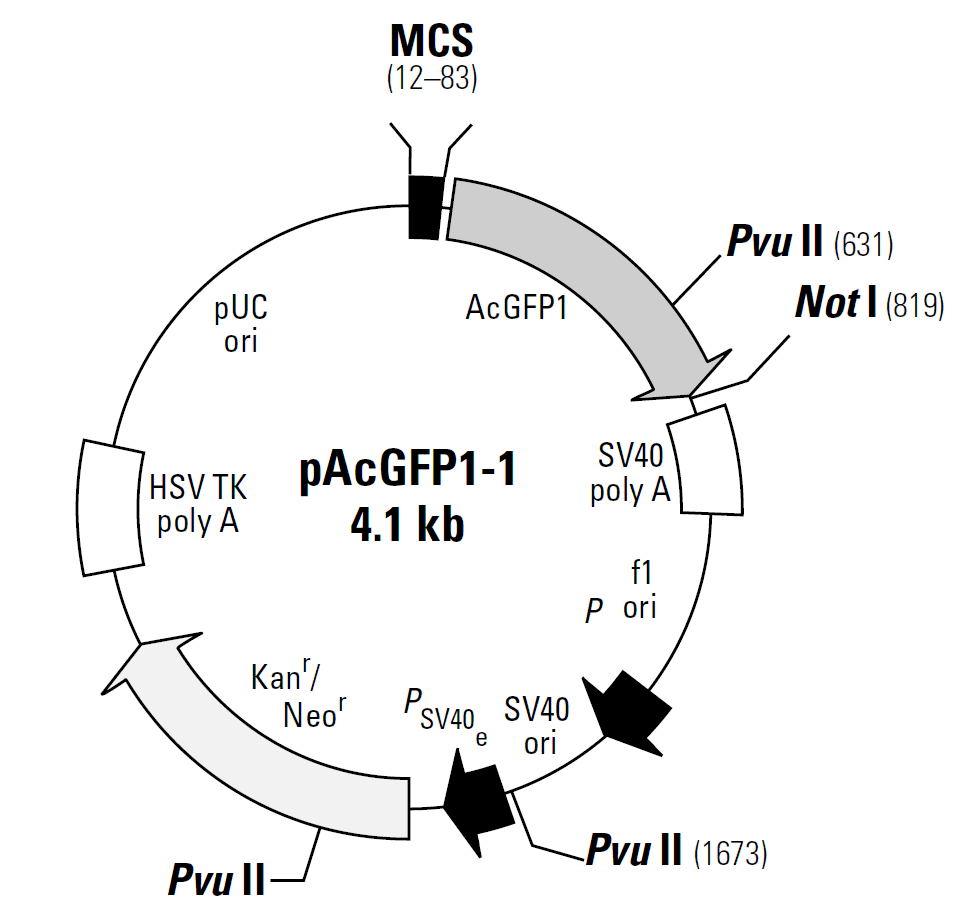



pAcGFP1-1质粒载体简介
pAcGFP1-1载体描述
pAcGFP1-1 encodes the green fluorescent protein AcGFP1, a derivative of AcGFP from Aequorea coerulescens. AcGFP1 has been optimized for brighter fluorescence. (Excitation maximum = 475 nm; emission maximum = 505 nm.) The coding sequence of the AcGFP1 gene contains silent base changes, which correspond to human codon-usage preferences (1). pAcGFP1-1 is a promoterless vector that can be used to monitor transcription from different promoters and promoter/enhancer combinations inserted into the multiple cloning site (MCS). Sequences upstream of AcGFP1 have been converted to a Kozak consensus translation initiation site (2) to enhance translation efficiency in eukaryotic cells. SV40 polyadenylation signals downstream of the AcGFP1 gene direct proper processing of the 3' end of the AcGFP1 mRNA. The vector backbone contains an SV40 origin for replication in mammalian cells expressing the SV40 T antigen, a pUC origin of replication for propagation in E. coli, and an f1 origin for single-stranded DNA production. A neomycin-resistance cassette (Neor) allows stably transfected eukaryotic cells to be selected using G418. This cassette consists of the SV40 early promoter, the neomycin/kanamycin resistance gene of Tn5, and polyadenylation signals from the Herpes simplex virus thymidine kinase (HSV TK) gene. A bacterial promoter upstream of the cassette expresses kanamycin resistance in E. coli.
AcGFP1 can be used as an in vivo reporter of gene expression. Promoters should be cloned into the pAcGFP1-1 MCS upstream from the AcGFP1 coding sequence. Without addition of a functional promoter, this vector will not express AcGFP1. The recombinant AcGFP1 vector can be transfected into mammalian cells using any standard method. If required, stable transfectants can be selected using G418 (3).
pAcGFP1-1载体含有以下元件:
MCS: 12–83
Aequorea coerulescens green fluorescent protein (AcGFP1) gene
Kozak consensus translation initiation site: 90–100
Start codon (ATG): 97–99; Stop codon: 814-816
SV40 early mRNA polyadenylation signal
Polyadenylation signals: 969–974 & 998–1003
mRNA 3' ends: 1007 & 1019
f1 single-strand DNA origin: 1066–1521
(Packages noncoding strand of AcGFP1-1.)
Ampicillin resistance (β-lactamase) promoter
–35 region: 1583–1588; –10 region: 1606–1611
Transcription start point: 1618
SV40 origin of replication: 1862–1997
SV40 early promoter
Enhancer (72-bp tandem repeats): 1693–1766 & 1767–1838
21-bp repeats: 1842–1862, 1863–1883 & 1885–1905
Early promoter element: 1918–1924
Major transcription start points: 1914, 1952, 1958 & 1963
Kanamycin/neomycin resistance gene
Neomycin phosphotransferase coding sequences:
Start codon (ATG): 2046–2048; stop codon: 2838–2840
G→A mutation to remove Pst I site: 2228
C→A (Arg→Ser) mutation to remove BssH II site: 2574
Herpes simplex virus (HSV) thymidine kinase (TK) polyadenylation signal
Polyadenylation signals: 3076–3081 & 3089–3094
pUC plasmid replication origin: 3425–4068
Propagation in E. Coli
Suitable host strains: DH5α, HB101 and other general purpose strains. Single-stranded DNA production requires
a host containing an F plasmid such as JM109 or XL1-Blue.
Selectable marker: plasmid confers resistance to kanamycin (50 μg/ml) in E. coli hosts.
E. coli replication origin: pUC
Copy number: ~500
pAcGFP1-1质粒序列载体序列
LOCUS pAcGFP1-1 4150 bp DNA SYN
DEFINITION pAcGFP1-1
ACCESSION
KEYWORDS
SOURCE
ORGANISM other sequences; artificial sequences; vectors.
FEATURES Location/Qualifiers
source 1..4150
/organism="pAcGFP1-1"
/mol_type="other DNA"
CDS 97..816
/label="ORF frame 1"
gene 100..813
/label="AcGFP1"
/gene="AcGFP1"
misc_feature 1029..1048
/label="EBV_rev_primer"
rep_origin complement(1198..1504)
/label="f1_origin"
promoter 1583..1611
/label="AmpR_promoter"
misc_feature complement(1677..1697)
/label="pBABE_3_primer"
misc_feature complement(1683..1898)
/label="SV40_enhancer"
promoter 1695..1963
/label="SV40_promoter"
rep_origin 1862..1939
/label="SV40_origin"
misc_feature 1924..1943
/label="SV40pro_F_primer"
CDS 2046..2840
/label="ORF frame 3"
gene 2049..2837
/label="NeoR/KanR"
/gene="NeoR/KanR"
CDS complement(2355..2891)
/label="ORF frame 3"
terminator 3015..3284
/label="TK_PA_terminator"
rep_origin 3432..4051
/label="pBR322_origin"
ORIGIN
1 TAGTTATTAC TAGCGCTACC GGACTCAGAT CTCGAGCTCA AGCTTCGAAT TCTGCAGTCG
61 ACGGTACCGC GGGCCCGGGA TCCACCGGTC GCCACCATGG TGAGCAAGGG CGCCGAGCTG
121 TTCACCGGCA TCGTGCCCAT CCTGATCGAG CTGAATGGCG ATGTGAATGG CCACAAGTTC
181 AGCGTGAGCG GCGAGGGCGA GGGCGATGCC ACCTACGGCA AGCTGACCCT GAAGTTCATC
241 TGCACCACCG GCAAGCTGCC TGTGCCCTGG CCCACCCTGG TGACCACCCT GAGCTACGGC
301 GTGCAGTGCT TCTCACGCTA CCCCGATCAC ATGAAGCAGC ACGACTTCTT CAAGAGCGCC
361 ATGCCTGAGG GCTACATCCA GGAGCGCACC ATCTTCTTCG AGGATGACGG CAACTACAAG
421 TCGCGCGCCG AGGTGAAGTT CGAGGGCGAT ACCCTGGTGA ATCGCATCGA GCTGACCGGC
481 ACCGATTTCA AGGAGGATGG CAACATCCTG GGCAATAAGA TGGAGTACAA CTACAACGCC
541 CACAATGTGT ACATCATGAC CGACAAGGCC AAGAATGGCA TCAAGGTGAA CTTCAAGATC
601 CGCCACAACA TCGAGGATGG CAGCGTGCAG CTGGCCGACC ACTACCAGCA GAATACCCCC
661 ATCGGCGATG GCCCTGTGCT GCTGCCCGAT AACCACTACC TGTCCACCCA GAGCGCCCTG
721 TCCAAGGACC CCAACGAGAA GCGCGATCAC ATGATCTACT TCGGCTTCGT GACCGCCGCC
781 GCCATCACCC ACGGCATGGA TGAGCTGTAC AAGTGAGCGG CCGCGACTCT AGATCATAAT
841 CAGCCATACC ACATTTGTAG AGGTTTTACT TGCTTTAAAA AACCTCCCAC ACCTCCCCCT
901 GAACCTGAAA CATAAAATGA ATGCAATTGT TGTTGTTAAC TTGTTTATTG CAGCTTATAA
961 TGGTTACAAA TAAAGCAATA GCATCACAAA TTTCACAAAT AAAGCATTTT TTTCACTGCA
1021 TTCTAGTTGT GGTTTGTCCA AACTCATCAA TGTATCTTAA GGCGTAAATT GTAAGCGTTA
1081 ATATTTTGTT AAAATTCGCG TTAAATTTTT GTTAAATCAG CTCATTTTTT AACCAATAGG
1141 CCGAAATCGG CAAAATCCCT TATAAATCAA AAGAATAGAC CGAGATAGGG TTGAGTGTTG
1201 TTCCAGTTTG GAACAAGAGT CCACTATTAA AGAACGTGGA CTCCAACGTC AAAGGGCGAA
1261 AAACCGTCTA TCAGGGCGAT GGCCCACTAC GTGAACCATC ACCCTAATCA AGTTTTTTGG
1321 GGTCGAGGTG CCGTAAAGCA CTAAATCGGA ACCCTAAAGG GAGCCCCCGA TTTAGAGCTT
1381 GACGGGGAAA GCCGGCGAAC GTGGCGAGAA AGGAAGGGAA GAAAGCGAAA GGAGCGGGCG
1441 CTAGGGCGCT GGCAAGTGTA GCGGTCACGC TGCGCGTAAC CACCACACCC GCCGCGCTTA
1501 ATGCGCCGCT ACAGGGCGCG TCAGGTGGCA CTTTTCGGGG AAATGTGCGC GGAACCCCTA
1561 TTTGTTTATT TTTCTAAATA CATTCAAATA TGTATCCGCT CATGAGACAA TAACCCTGAT
1621 AAATGCTTCA ATAATATTGA AAAAGGAAGA GTCCTGAGGC GGAAAGAACC AGCTGTGGAA
1681 TGTGTGTCAG TTAGGGTGTG GAAAGTCCCC AGGCTCCCCA GCAGGCAGAA GTATGCAAAG
1741 CATGCATCTC AATTAGTCAG CAACCAGGTG TGGAAAGTCC CCAGGCTCCC CAGCAGGCAG
1801 AAGTATGCAA AGCATGCATC TCAATTAGTC AGCAACCATA GTCCCGCCCC TAACTCCGCC
1861 CATCCCGCCC CTAACTCCGC CCAGTTCCGC CCATTCTCCG CCCCATGGCT GACTAATTTT
1921 TTTTATTTAT GCAGAGGCCG AGGCCGCCTC GGCCTCTGAG CTATTCCAGA AGTAGTGAGG
1981 AGGCTTTTTT GGAGGCCTAG GCTTTTGCAA AGATCGATCA AGAGACAGGA TGAGGATCGT
2041 TTCGCATGAT TGAACAAGAT GGATTGCACG CAGGTTCTCC GGCCGCTTGG GTGGAGAGGC
2101 TATTCGGCTA TGACTGGGCA CAACAGACAA TCGGCTGCTC TGATGCCGCC GTGTTCCGGC
2161 TGTCAGCGCA GGGGCGCCCG GTTCTTTTTG TCAAGACCGA CCTGTCCGGT GCCCTGAATG
2221 AACTGCAAGA CGAGGCAGCG CGGCTATCGT GGCTGGCCAC GACGGGCGTT CCTTGCGCAG
2281 CTGTGCTCGA CGTTGTCACT GAAGCGGGAA GGGACTGGCT GCTATTGGGC GAAGTGCCGG
2341 GGCAGGATCT CCTGTCATCT CACCTTGCTC CTGCCGAGAA AGTATCCATC ATGGCTGATG
2401 CAATGCGGCG GCTGCATACG CTTGATCCGG CTACCTGCCC ATTCGACCAC CAAGCGAAAC
2461 ATCGCATCGA GCGAGCACGT ACTCGGATGG AAGCCGGTCT TGTCGATCAG GATGATCTGG
2521 ACGAAGAGCA TCAGGGGCTC GCGCCAGCCG AACTGTTCGC CAGGCTCAAG GCGAGCATGC
2581 CCGACGGCGA GGATCTCGTC GTGACCCATG GCGATGCCTG CTTGCCGAAT ATCATGGTGG
2641 AAAATGGCCG CTTTTCTGGA TTCATCGACT GTGGCCGGCT GGGTGTGGCG GACCGCTATC
2701 AGGACATAGC GTTGGCTACC CGTGATATTG CTGAAGAGCT TGGCGGCGAA TGGGCTGACC
2761 GCTTCCTCGT GCTTTACGGT ATCGCCGCTC CCGATTCGCA GCGCATCGCC TTCTATCGCC
2821 TTCTTGACGA GTTCTTCTGA GCGGGACTCT GGGGTTCGAA ATGACCGACC AAGCGACGCC
2881 CAACCTGCCA TCACGAGATT TCGATTCCAC CGCCGCCTTC TATGAAAGGT TGGGCTTCGG
2941 AATCGTTTTC CGGGACGCCG GCTGGATGAT CCTCCAGCGC GGGGATCTCA TGCTGGAGTT
3001 CTTCGCCCAC CCTAGGGGGA GGCTAACTGA AACACGGAAG GAGACAATAC CGGAAGGAAC
3061 CCGCGCTATG ACGGCAATAA AAAGACAGAA TAAAACGCAC GGTGTTGGGT CGTTTGTTCA
3121 TAAACGCGGG GTTCGGTCCC AGGGCTGGCA CTCTGTCGAT ACCCCACCGA GACCCCATTG
3181 GGGCCAATAC GCCCGCGTTT CTTCCTTTTC CCCACCCCAC CCCCCAAGTT CGGGTGAAGG
3241 CCCAGGGCTC GCAGCCAACG TCGGGGCGGC AGGCCCTGCC ATAGCCTCAG GTTACTCATA
3301 TATACTTTAG ATTGATTTAA AACTTCATTT TTAATTTAAA AGGATCTAGG TGAAGATCCT
3361 TTTTGATAAT CTCATGACCA AAATCCCTTA ACGTGAGTTT TCGTTCCACT GAGCGTCAGA
3421 CCCCGTAGAA AAGATCAAAG GATCTTCTTG AGATCCTTTT TTTCTGCGCG TAATCTGCTG
3481 CTTGCAAACA AAAAAACCAC CGCTACCAGC GGTGGTTTGT TTGCCGGATC AAGAGCTACC
3541 AACTCTTTTT CCGAAGGTAA CTGGCTTCAG CAGAGCGCAG ATACCAAATA CTGTCCTTCT
3601 AGTGTAGCCG TAGTTAGGCC ACCACTTCAA GAACTCTGTA GCACCGCCTA CATACCTCGC
3661 TCTGCTAATC CTGTTACCAG TGGCTGCTGC CAGTGGCGAT AAGTCGTGTC TTACCGGGTT
3721 GGACTCAAGA CGATAGTTAC CGGATAAGGC GCAGCGGTCG GGCTGAACGG GGGGTTCGTG
3781 CACACAGCCC AGCTTGGAGC GAACGACCTA CACCGAACTG AGATACCTAC AGCGTGAGCT
3841 ATGAGAAAGC GCCACGCTTC CCGAAGGGAG AAAGGCGGAC AGGTATCCGG TAAGCGGCAG
3901 GGTCGGAACA GGAGAGCGCA CGAGGGAGCT TCCAGGGGGA AACGCCTGGT ATCTTTATAG
3961 TCCTGTCGGG TTTCGCCACC TCTGACTTGA GCGTCGATTT TTGTGATGCT CGTCAGGGGG
4021 GCGGAGCCTA TGGAAAAACG CCAGCAACGC GGCCTTTTTA CGGTTCCTGG CCTTTTGCTG
4081 GCCTTTTGCT CACATGTTCT TTCCTGCGTT ATCCCCTGAT TCTGTGGATA ACCGTATTAC
4141 CGCCATGCAT
//
pAcGFP1-1载体图谱质粒图谱pdf版和pAcGFP1-1载体序列质粒序列等相关资料下载
pAcGFP1-1质粒载体应用举例
- 上一篇:pCantab 5E
- 下一篇:pDsRed2-1

